Komputasi Modern
I. Apa yang kamu ketahui tentang komputasi modern?
Komputasi modern merupakan satu kesatuan arti yang terdiri dari dua kata penyusun, yaitu kata komputasi dan modern. Komputasi merupakan sebuah cara untuk menemukan pemecahan dari sebuah permasalahan input data dengan menggunakan algoritma. Pada zaman dahulu, komputasi dan perhitungan data dan angka masih menggunakan alat tulis biasa, kertas kosong, atau dikerjakan dengan menggunakan tabel. Komputasi yang disebut modern adalah komputasi yang menggunakan peralatan canggih dan tepat saat menyelesaian perhitungan data.
Dri penjabaran di atas saya dapat simpulkan bahwa Komputasi Modern merupakan sebuah cara perhitungan data yang menggunakan peralatan canggih seperti komputer dan sebagainya dimana tersimpan sejumlah algoritma di dalamnya yang dapat berfungsi untuk memecahkan dan menyelesaikan permasalahan perhitungan yang lebih efisien dan efektif.Masalah perhitungan yang sering kita temui diantaranya adalah sebagai berikut :
- Kecepatan Gelombang Fisika (dalam satuan Hz)
- Teori Kompleksitas Big O
- Permasalahan perhitungan volume Hambatan listrik secara paralel
II. Jelaskan sejarah komputasi modern!
Tanpa kita sadari, Komputasi sebenarnya telah dapat kita lakukan sejak dahulu. Perhitungan komputasi sederhana seperti menambahkan, mengalikan dan mengurangi data adalah kegiatan sehari-hari yang kita lakukan di sekolah maupun perkuliahan. Zaman dahulu, manusia purba seperti Pithecantropus Erectus, Meganthropus Paleo Javanicus, hingga Homo Sapiens telah pandai melakukan perhitungan sederhana untuk sistem jual beli tanpa menggunakan uang (barter atau pertukaran barang). Perhitungan hebat dari zaman dahulu yang masih sering kita gunakan seperti :
- Sistem perhitungan kalender Masehi
- Kalender Islam (Hijriah)
- Rasi bintang zaman romawi
Pada pertengahan abad 20, banyak kebutuhan komputasi ilmiah bertemu dengan diiringi perkembangan komputer analog yang menggunakan mekanis atau listrik langsung model masalah sebagai dasar perhitungan. Namun komputer ini tidak dapat diatur secara program dan umumnya tidak memiliki fleksibilitas dan keakuratan komputer digital modern.

George stibitz secara internasional diakui sebagai ayah dari komputer digital modern. Goerge bekerja di laboratorium bel di November 1937, beliau menciptakan dan membangun sebuah relay berbasis kalkulator yang dijuluki sebagai "model k" (untuk "meja dapur", di mana ia telah berkumpul). Goerge adalah orang pertama yang menggunakan sirkuit biner untuk melakukan operasi aritmatika. Kemudian ia menambahkan model kecanggihan yang lebih besar termasuk aritmatika dan kemampuan pemrograman kompleks.

Tokoh lain yang sangat mempengaruhi perkembangan komputasi modern adalah John von Neumann (1903-1957). Beliau adalah ilmuan yang meletakkan dasar-dasar komputer modern. Von Neumann telah menjadi ilmuwan besar abad 21. Von Neumann memberikan berbagai sumbangan ilmu pengetahuan dalam bidang matematika, teori kuantum, game theory, fisika nuklir, dan ilmu komputer yang di salurkan melalui karya-karyanya . Beliau merupakan salah satu ilmuwan yang terkait dalam pembuatan bom atom di Los Alamos pada Perang Dunia II lalu. Kegeniusannya dalam matematika telah terlihat semenjak kecil dengan mampu melakukan pembagian bilangan delapan digit (angka) di dalam kepalanya.
III. Sebutkan macam-macam komputasi modern!
Komputasi memiliki 3 model, yaitu :
- Mesin Mealy
- Mesin Moore
- Petri net
Mesin Mealy

Diagram Fase Sederhana dari Mesin Mealy
Mesin Mealy adalah otomasi fasa berhingga (finite state automaton atau finite state tranducer) yang menghasilkan keluaran berdasarkan fasa saat itu dan bagian masukan/input. Dalam hal ini, diagram fasa (state diagram) dari mesin Mealy memiliki sinyal masukan dan sinyal keluaran untuk tiap transisi. Prinsip ini berbeda dengan mesin Moore yang hanya menghasilkan keluaran/output pada tiap fasa.
Nama Mealy diambil dari “G. H. Mealy” seorang perintis mesin-fasa (state-machine) yang menulis karangan “A Method for Synthesizing Sequential Circuits” pada tahun 1955.
Mesin Moore

Diagram Fase Sederhana dari Mesin Moore
Mesin Moore adalah otomasi fasa berhingga (finite state automaton) di mana keluarannya ditentukan hanya oleh fasa saat itu (dan tidak terpengaruh oleh bagian masukan/input). Diagram fasa (state diagram) dari mesin Moore memiliki sinyal keluaran untuk masing-masing fasa. Hal ini berbeda dengan mesin Mealy yang mempunyai keluaran untuk tiap transisi.
Nama Moore diambil dari “Edward F. Moore” seorang ilmuwan komputer dan perintis mesin-fasa (state-machine) yang menulis karangan “Gedanken-experiments on Sequential Machines”.
Petri net

Contoh Animasi Petri net Otodidak
Petri net adalah salah satu model untuk merepresentasikan sistem terdistribusi diskret. Sebagai sebuah model, Petri net merupakan grafik 2 arah yang terdiri dari place, transition, dan tanda panah yang menghubungkan keduanya. Di samping itu, untuk merepresentasikan keadaan sistem, token diletakkan pada place tertentu. Ketika sebuah transition terpantik, token akan bertransisi sesuai tanda panah.
Contoh Penggunaan dalam Dunia Kedokteran
Contoh penggunaan komputasi modern dalam bidang kedokteran adalah USG Scan.
Untuk meramalkan aktivitas dari janin atau calon bayi, seorang praktisi komputasi meniru suasana pengujian aktivitasnya di laboratorium basah dengan model-model Fisika atau Matematika (seperti: struktur 3 dimensi bagian rahim seorang ibu) sebagai pengganti rahim sesungguhnya pada laboratorium tersebut. Model-model ini kemudian dinyatakan di dalam persamaan-persamaan Matematika yang kemudian diselesaikan oleh komputer dengan kapasitas dan kelajuan yang melebihi kapasitas dan kelajuan manusia. Berikut ini merupakan contoh USG Scan terbaru dan terkecil yang saya dapat dari perkembangan teknologi yang semakin pesat.
USG Scanner Terkecil Sebesar Handphone

Kemajuan teknologi Kedokteran terus berkembang, General Electric (GE), mengumumkan sebuah produk Baru yang sangat membantu, dalam memberikan diagnosa cepat dalam pertolongan kepada pasien. Vscan adalah produk baru, merupakan USG Scanner terkecil, ukurannya tidak lebih dari sebuah Handphone. Diharapkan Produk ini dapat menekan biaya pemeriksaan Scanner, selama ini ukuran USG Scanner cukup besar dan hanya ada di Rumah Sakit, Klinik.
"Ini tentang ukuran yang sama seperti BlackBerry," kata Immelt, sambil mengangkat perangkat putih yang tampaknya lipat di tengah seperti flip-telepon. Bagian atas menunjukkan perangkat gambar USG (informasi dari hati pasien,), sedangkan bagian bawah fungsi tombol kontrol.
Kemajuan teknologi Kesehatan ini diharapkan akan membantuk diagnosis cepat dan akurat, sehingga pertolongan terhadap pasien dapat dilakukan dengan baik. Selama ini, pemeriksaan Scan hanya dapat dilakukan di Rumah Sakit, pada banyak kasus, pertolongan yang dilakukan menjadi terlambat. Pasien tidak dapat diselamatkan.

Parallel Processing
I. Apa yang kamu ketahui tentang komputasi?
Parallel komputasi adalah melakukan perhitungan komputasi dengan menggunakan 2 atau lebih CPU/Processor dalam suatu komputer yang sama atau komputer yang berbeda dimana dalam hal ini setiap instruksi dibagi kedalam beberapa instruksi kemudian dikirim ke processor yang terlibat komputasi dan dilakukan secara bersamaan. Untuk proses pembagian proses komputasi tersebut dilakukan oleh suatu software yang betugas untuk mengatur komputasi dalam hal makalah ini akan digunakan Message Parsing Interface (MPI).
Berikut ini adalah gambar perbedaan antara komputasi tunggal dengan parallel komputasi :
a) komputasi tunggal/serial

b) komputasi parallel
Gambar 1. Perbandingan antara serial komputasi dan parallel komputasi
II. Apa yang kamu ketahui tentang parallel processing?
Pemrosesan parallel (parallel processing) adalah penggunaan lebih dari satu CPU untuk menjalankan sebuah program secara lebih dari satu CPU untuk menjalankan sebuah program secara simultan. Idealnya, parallel processing membuat program berjalan lebih cepat karena semakin banyak CPU yang digunakan. Tetapi dalam praktek, seringkali sulit membagi program sehingga dapat dieksekusi oleh CPU yang berbeda-beda tanpa berkaitan di antaranya. Sebagian besar komputer hanya mempunyai satu CPU, namun ada yang mempunyai lebih dari satu Bahkan juga ada komputer dengan ribuan CPU. Komputer dengan satu CPU dapat melakukan parallel processing dengan menghubungkannya dengan komputer lain pada jaringan. Namun, parallel processing ini memerlukan software canggih yang disebut distributed processing software. Parallel processing berbeda dengan multitasking, yaitu satu CPU mengeksekusi beberapa program sekaligus. Parallel processing disebut juga parallel .
Pemrograman paralel adalah teknik pemrograman komputer yang memungkinkan eksekusi perintah/operasi secara bersamaan (komputasi paralel), baik dalam komputer dengan satu (prosesor tunggal) ataupun banyak (prosesor ganda dengan mesin paralel) CPU. Bila komputer yang digunakan secara bersamaan tersebut dilakukan oleh komputer-komputer terpisah yang terhubung dalam suatu jaringan komputer lebih sering istilah yang digunakan adalah sistem terdistribusi (distributed computing).
Tujuan utama dari pemrograman paralel adalah untuk meningkatkan performa komputasi. Semakin banyak hal yang bisa dilakukan secara bersamaan (dalam waktu yang sama), semakin banyak pekerjaan yang bisa diselesaikan.
Paralel prosessing komputasi adalah proses atau pekerjaan komputasi di komputer dengan memakai suatu bahasa pemrograman yang dijalankan secara paralel pada saat bersamaan. Secara umum komputasi paralel diperlukan untuk meningkatkan kecepatan komputasi bila dibandingkan dengan pemakaian komputasi pada komputer tunggal. Penggunaan komputasi parallel prosessing merupakan pilihan yang cukup handal untuk saat ini untuk pengolahan data yang besar dan banyak.
Aspek keamanan merupakan suatu aspek penting dalam sistem parallel prosessing komputasi ini, karena didalam sistem akan banyak berkaitan dengan akses data, hak pengguna, keamanan data, keamanan jaringan terhadap peyerangan sesorang atau bahkan virus sehingga akan menghambat kinerja dari system komputasi ini. Didalam makalah ini akan memamparkan bagaimana sistem komputasi parallel ini pada suatu PC Cluster sehingga menjadi suatu sistem komputasi yang aman sehingga dapat meningkatkan performa dari komputasi.
Implementasi untuk parallel komputasi ini telah dilakukan di lab dengan PC Clutster dengan menggunakan 1 buah master node dan 7 buah slave node, dimana system yang digunakan adalah diskless dengan menggunakan switch hub 1Gbps sebagai konsentrator dan dengan menerapkan aspek keamanan.
III. Jelaskan hubungan antara komputasi modern dengan parallel processing!
PC Cluster
PC Cluster adalah sebuah sistem komputer yang terdiri dari beberapa PC (Personal Computer) yang dikoneksi dalam satu jaringan untuk melakukan sebuah pekerjaan komputasi ataupun simulasi secara bersama-sama. Setiap PC menjadi satu unit prosesor dengan masing-masing memiliki memori dari sebuah mesin komputasi paralel.
Pada sistem komputasi parallel terdiri dari beberapa unit prosesor dan beberapa unit memori. Ada dua teknik yang berbeda untuk mengakses data di unit memori, yaitu shared memory address dan message passing. Berdasarkan cara mengorganisasikan memori ini komputer paralel dibedakan menjadi shared memory parallel machine dan distributed memory parallel machine.
Prosesor dan memori ini didalam mesin paralel dapat dihubungkan (interkoneksi) secara statis maupun dinamis. Interkoneksi statis umumnya digunakan oleh distributed memory system (sistem memori terdistribusi). Sambungan langsung peer to peer digunakan untuk menghubungkan semua prosesor. Interkoneksi dinamis umumnya menggunakan switch untuk menghubungkan antar prosesor dan memori.
Pada jaringan komputer ada istilah yang biasa digunakan dalam merancang jaringan interkoneksi statis. Istilah pertama adalah topology, yaitu tipe struktur interkoneksi jaringan komputer. Network topology yang umum dikenal adalah linear, ring, 2D/3D-mesh, torus, cube dan star topology.
Selain itu ada istilah yang digunakan sebagai parameter jaringan interkoneksi statis seperti istilah connectivity, yaitu jumlah terkecil sambungan yang harus diputus untuk membagi jaringan menjadi dua buah jaringan yang terpisah; dan istilah diameter, yaitu jumlah sambungan yang harus dilalui oleh sebuah data yang dikirim ke unit prosesor terjauh melalui jalan terpendeknya (the shortest path).
Topologi Ring
Dimana topologi ring ini berbentuk lingkaran, dimana satu komputer dengan computer lain akan terhubung secara berantai sehingga terbentuk suatu ring yang yang besar. Dimana ring node topologi connectivity = 2 dan Diamenter = n/2 jika genap dan (n-1)/2 bila n ganjil.
Dua buah fungsi jaringan harus terpenuhi agar mesin PC Cluster dapat menjalankan tugas komputasi paralelnya, yaitu komunikasi dan remote access antar unit prosesor.
Fungsi komunikasi antar unit prosesor mutlak diperlukan karena pada sistem paralel dengan memori terdistribusi, perpindahan data (message passing) antar unit prosesor merupakan hal multak yang tak terpisahkan. Fungsi ini terpenuhi dengan mengintegrasikan unit-unit prosesor melalui Gigabit Ethernet Card dan Ethernet Cable.
Jika pada interkoneksi dinamis setiap unit menggunakan satu ethernet card dengan straight cable terkoneksi ke sebuah 1000Mbit/s switch, maka pada interkoneksi statis diperlukan dua ethernet card untuk linear topology maupun ring, empat ethernet card untuk 2-D mesh topology maupun torus. Untuk interkoneksi statis, kabel ethernet disambung secara cross.
Fungsi komunikasi dengan menggunakan switch jauh lebih mudah dimplementasikan, karena switch berfungsi sebagai router dari komunikasi jaringannya. Untuk interkoneksi statis, karena koneksi jaringan adalah peer to peer, maka untuk komunikasi jaringan dari satu unit ke unit yang lain yang tidak berhubungan langsung (peer to peer) harus dilakukan routing secara eksplisit pada sistem jaringannya, yaitu dengan menggunakan fungsi gateway dan bridging.
Komunikasi data pada sistem paralel memori terdistribusi, memerlukan alat bantu komunikasi. Alat bantu yang sering digunakan oleh sistem seperti PC Jaringan pada saat ini adalah standar MPI (Message Passing Interface) atau standar PVM (Parallel Virtual Machine)yang keduanya bekerja diatas TCP/IP communication layer. Kedua standar ini memerlukan fungsi remote access agar dapat menjalankan program pada masing-masing unit prosesor.
Network File System (NFS)
Salah satu protocol yang dipergunakan pada komputasi parallel adalah Network File System (NFS), NFS adalah protokol yang dapat membagi sumber daya melalui jaringan. NFS dibuat untuk dapat independent dari jenis mesin, jenis sistem operasi, dan jenis protokol transport yang digunakan. Hal ini dilakukan dengan menggunakan RPC.
NFS memperbolehkan user yang telah diijinkan untuk mengakses file-file yang berada di remote host seperti mengakses file yang berada di lokal. Protokol yang digunakan protokol mount menentukan host remote dan jenis file sistem yang akan diakses dan menempatkan di suatu direktori, protokol NFS melakukan I/O pada remote file system.
Protokol mount dan protokol NFS bekerja dengan menggunakan RPC dan mengirim dengan protokol TCP dan UDP.
Kegunaan dari NFS pada komputasi parallel adalah untuk melakukan sharing data sehingga setiap node slave dapat mengakses program yang sama pada node master.
Secure Shell (SSH)
Secure shell (SSH) adalah protokol standar yang membentuk jalur yang aman pada komunikasi antar komputer. SSH menggunakan teknik enkripsi public key pada sistem authentikasi pengguna untuk mengakses komputer yang lain. SSH memberikan sistem enkripsi pada jalur yang digunakan, sehingga memberikan tingkat keamanan data yang tinggi. SSH biasa digunakan untuk melakukan remote login dan menjalankan perintah pada komputer remote, tetapi SSH juga dapat digunakan sebagai tunnel jaringan, melakukan penerusan pada port TCP, dan koneksi X11. Selain itu dapat juga digunakan untuk mentransfer suatu file dengan protokol SFTP atau SCP. SSH server bekerja pada port 22.
Trivial File Transfer Protocol (TFTP) Server
TFTP merupakan standar protokol dengan STD nomer 33. Dijelaskan pada RFC 1350 – The TFTP Protocol. Dan diupdate pada RFC 1785, 2347, 2348, dan 2349.
Transfer TFTP adalah transfer file antar disk (disk-to-disk), dengan menggunakan API SENDFILE. TFTP menggunakan protokol UDP. TFTP client melakukan inisialisasi dengan mengirim permintaan untuk read/write melalui port 69, kemudian server dan client melakukan negosiasi tentang port yang akan digunakan untuk melakukan transfer file.
Dynamic Host Configuration Protocol (DHCP) Server
DHCP memberikan framework untuk disampaikan kepada client yang berisikan informasi tentang konfigurasi jaringan. DHCP bekerja berdasarkan protokol BOOTP, dimana ditambahkan fungsi untuk mengalokasikan penggunaan IP address dan konfigurasi jaringan lainnya.
Spesifikasi DHCP dapat dilihat pada RFC 2131 – Dynamic Host Configuration Protocol, dan RFC 2132 – DHCP options and BOOTP vendor extension.DHCP melakukan transaksi dengan melihat pada jenis pesan yang dikirimkan.
Rancangan PC Cluster ini meliputi pemilihan topologi, pemilihan sistem diskless dengan memanfaatkan BOOTROM pada Ethernet, pemilihan dan installasi Sistem Operasi (OS) yang dipergunakan, pemilihan hardware network, pemilihan dan installasi compiler program dan setting terhadap keamanan system yang ada terutama pada system operasi Linux.
Instalasi Sistem Operasi
Sistem operasi yang dapat digunakan untuk cluster dapat bervariasi, mulai dari Linux, FreeBSD, Sun OS dll. Pada rancangan ini hanya dijelaskan pembangunan cluster dengan menggunakan satu operating sistem, yaitu SuSE ESLES versi 9. Install Linux SuSE ESLES dengan opsi installasi minimum sebagai berikut:
- Programming
- Network
Pemilihan Topologi Jaringan
Berbagai topologi dapat digunakan dalam pembangunan komputer cluster. Topologi cube dan hypercube dapat digunakan untuk membangun komputer cluster 4 dan 8 komputer dengan tanpa menggunakan switch hub. Pada topologi hypercube tiap komputer memerlukan minimal 2 network card, sedang untuk topologi hypercube, tiap komputer memerlukan minimal 3 network card. Salah satu komputer dari topologi tersebut perlu mempunyai network card tambahan untuk koneksi jaringan komputer cluster dengan jaringan di luar.
Untuk perancangan ini kita menggunakan topologi hub maka otomatis topologinya menjadi hubungan peer-to-peer, dimana tiap komputer terhubung interkoneksi satu sama lain. Dalam hubungan dengan menggunakan switch hub, setiap komputer hanya perlu satu network card. Penggunaan switch hub dapat meningkatkan performansi dari cluster karena tiap-tiap komputer terhubung langsung satu sama lain (jarak koneksi = 1). Jarak koneksi terjauh dari topologi cube adalah 2, sedang untuk topologi hypercube adalah 3.
Setting Node Master
Setelah komputer terkoneksi dalam jaringan, langkah berikutnya adalah membangun hubungan jaringan, sehingga memungkinkan setiap komputer pendukung cluster dapat berkomunikasi data satu sama lain. Pada sistem PC Cluster ini akan digunakan sistem diskless sehingga kita hanya cukup melakukan installasi OS terhadap 1 server yang bertindak sebagai master node, dimana pada master node ini berfungsi sebagai :
1. DHCP server dengan options support PXEBOOT
2. TFTP server berfungsi untuk melakukan transfer file antara disk – to – disk untuk melakukan booting PXEBOOT
3. NFS server untuk melakukan sharing data terhadap node slave
4. FTP server sebagai file transfer memindahkan data
5. Installasi PGI CDK untuk aplikasi parallel komputasi
6. Lakukan compilasi kernel bila diperlukan
Setting Node Slave
Selain node master ada juga yang disebut sebagai node slave, dimana node slave ini berfungsi node yang melakukan parallel komputasi. Pada node slave ini tidak memerlukan hardisk, tetapi menggunakan diskless dimana booting terhadap OS dilakukan melalui jaringan yang diambil dari node master.
Komputer pada node slave ini minimal harus memiliki 1 ethernet card yang support melakukan PXEBOOT, sehingga dapat melakukan booting melalui jaringan.
Kesimpulan dari tulisan ini adalah sebagai berikut :
- Parallel Komputasi dengan menggunakan PC Cluster merupakan salah satu solusi untuk melakukan komputasi dalam jumlah yang besar, sehingga perlu dilakukan management sistem keamanan yang ada pada PC Cluster tersebut.
- Keamanan Sistem merupakan hal yang terpenting didalam melakukan parallel komputasi terutama dengan menggunakan PC Cluster, sehingga pengaturan untuk akses data, hak re/write dilakukan pengaturan.
- Solusi PC Cluster dengan menggunakan diskless merupakan salah satu solusi yang aman dalam melakukan parallel komputasi, karena semua data tersimpan pada server master node yang system keamanannya sangat terjaga dan terlindung.
Bio Informatika
I. Apa saja penerapan utama dalam BioInformatika?
Sesuai dengan jenis informasi biologis yang disimpannya, basis data sekuens biologis dapat berupa basis data primer untuk menyimpan sekuens primer asam nukleat maupun protein, basis data sekunder untuk menyimpan motif sekuens protein, dan basis data struktur untuk menyimpan data struktur protein maupun asam nukleat.
Basis data utama untuk sekuens asam nukleat saat ini adalah GenBank (Amerika Serikat), EMBL (Eropa), dan DDBJ(Inggris) (DNA Data Bank of Japan, Jepang). Ketiga basis data tersebut bekerja sama dan bertukar data secara harian untuk menjaga keluasan cakupan masing-masing basis data. Sumber utama data sekuens asam nukleat adalah submisi langsung dari periset individual, proyek sekuensing genom, dan pendaftaran paten. Selain berisi sekuens asam nukleat, entri dalam basis data sekuens asam nukleat umumnya mengandung informasi tentang jenis asam nukleat (DNA atau RNA), nama organisme sumber asam nukleat tersebut, dan pustaka yang berkaitan dengan sekuens asam nukleat tersebut.
Sementara itu, contoh beberapa basis data penting yang menyimpan sekuens primer protein adalah PIR (Protein Information Resource, Amerika Serikat), Swiss-Prot (Eropa), dan TrEMBL (Eropa). Ketiga basis data tersebut telah digabungkan dalam UniProt (yang didanai terutama oleh Amerika Serikat). Entri dalam UniProt mengandung informasi tentang sekuens protein, nama organisme sumber protein, pustaka yang berkaitan, dan komentar yang umumnya berisi penjelasan mengenai fungsi protein tersebut.
BLAST(Basic Local Alignment Search Tool) merupakan perkakas bioinformatika yang berkaitan erat dengan penggunaan basis data sekuens biologis. Penelusuran BLAST (BLAST search) pada basis data sekuens memungkinkan ilmuwan untuk mencari sekuens asam nukleat maupun protein yang mirip dengan sekuens tertentu yang dimilikinya. Hal ini berguna misalnya untuk menemukan gen sejenis pada beberapa organisme atau untuk memeriksa keabsahan hasil sekuensing maupun untuk memeriksa fungsi gen hasil sekuensing. Algoritma yang mendasari kerja BLAST adalah penyejajaran sekuens.
PDB (Protein Data Bank, Bank Data Protein) adalah basis data tunggal yang menyimpan model struktural tiga dimensi protein dan asam nukleat hasil penentuan eksperimental (dengan kristalografi sinar-X, spektroskopi NMR dan mikroskopi elektron). PDB menyimpan data struktur sebagai koordinat tiga dimensi yang menggambarkan posisi atom-atom dalam protein ataupun asam nukleat.
Sequence alignment merupakan metode dasar dalam analisis sekuens. Metode ini digunakan untuk mempelajari evolusi sekuens-sekuens dari leluhur yang sama (common ancestor). Ketidakcocokan (mismatch) dalam alignment diasosiasikan dengan proses mutasi, sedangkan kesenjangan (gap, tanda "–") diasosiasikan dengan proses insersi atau delesi. Sequence alignment memberikan hipotesis atas proses evolusi yang terjadi dalam sekuens-sekuens tersebut. Misalnya, kedua sekuens dalam contoh alignment di atas bisa jadi berevolusi dari sekuens yang sama "ccatgggcaac". Dalam kaitannya dengan hal ini, alignment juga dapat menunjukkan posisi-posisi yang dipertahankan (conserved) selama evolusi dalam sekuens-sekuens protein, yang menunjukkan bahwa posisi-posisi tersebut bisa jadi penting bagi struktur atau fungsi protein tersebut.
Selain itu, sequence alignment juga digunakan untuk mencari sekuens yang mirip atau sama dalam basis data sekuens. BLAST adalah salah satu metode alignment yang sering digunakan dalam penelusuran basis data sekuens. BLAST menggunakan algoritma heuristik dalam penyusunan alignment.
Beberapa metode alignment lain yang merupakan pendahulu BLAST adalah metode "Needleman-Wunsch" dan "Smith-Waterman". Metode Needleman-Wunsch digunakan untuk menyusun alignment global di antara dua atau lebih sekuens, yaitu alignment atas keseluruhan panjang sekuens tersebut. Metode Smith-Waterman menghasilkan alignment lokal, yaitu alignment atas bagian-bagian dalam sekuens. Kedua metode tersebut menerapkan pemrograman dinamik (dynamic programming) dan hanya efektif untuk alignment dua sekuens (pairwise alignment).
Clustal adalah program bioinformatika untuk alignment multipel (multiple alignment), yaitu alignment beberapa sekuens sekaligus. Dua varian utama Clustal adalah ClustalW dan ClustalX.
Metode lain yang dapat diterapkan untuk alignment sekuens adalah metode yang berhubungan dengan Hidden Markov Model ("Model Markov Tersembunyi", HMM). HMM merupakan model statistika yang mulanya digunakan dalam ilmu komputer untuk mengenali pembicaraan manusia (speech recognition). Selain digunakan untuk alignment, HMM juga digunakan dalam metode-metode analisis sekuens lainnya, seperti prediksi daerah pengkode protein dalam genom dan prediksi struktur sekunder protein.
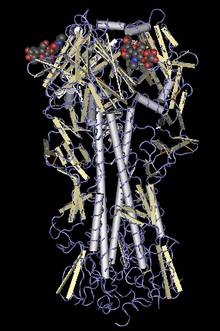

Secara kimia/fisika, bentuk struktur protein diungkap dengan kristalografi sinar-X ataupun spektroskopi NMR, namun kedua metode tersebut sangat memakan waktu dan relatif mahal. Sementara itu, metode sekuensing protein relatif lebih mudah mengungkapkan sekuens asam amino protein. Prediksi struktur protein berusaha meramalkan struktur tiga dimensi protein berdasarkan sekuens asam aminonya (dengan kata lain, meramalkan struktur tersier dan struktur sekunder berdasarkan struktur primer protein). Secara umum, metode prediksi struktur protein yang ada saat ini dapat dikategorikan ke dalam dua kelompok, yaitu metode pemodelan protein komparatif dan metode pemodelan de novo.
Pemodelan protein komparatif (comparative protein modelling) meramalkan struktur suatu protein berdasarkan struktur protein lain yang sudah diketahui. Salah satu penerapan metode ini adalah pemodelan homologi (homology modelling), yaitu prediksi struktur tersier protein berdasarkan kesamaan struktur primer protein. Pemodelan homologi didasarkan pada teori bahwa dua protein yang homolog memiliki struktur yang sangat mirip satu sama lain. Pada metode ini, struktur suatu protein (disebut protein target) ditentukan berdasarkan struktur protein lain (protein templat) yang sudah diketahui dan memiliki kemiripan sekuens dengan protein target tersebut. Selain itu, penerapan lain pemodelan komparatif adalah protein threading yang didasarkan pada kemiripan struktur tanpa kemiripan sekuens primer. Latar belakang protein threading adalah bahwa struktur protein lebih dikonservasi daripada sekuens protein selama evolusi; daerah-daerah yang penting bagi fungsi protein dipertahankan strukturnya. Pada pendekatan ini, struktur yang paling kompatibel untuk suatu sekuens asam amino dipilih dari semua jenis struktur tiga dimensi protein yang ada. Metode-metode yang tergolong dalam protein threading berusaha menentukan tingkat kompatibilitas tersebut.
Dalam pendekatan de novo atau ab initio, struktur protein ditentukan dari sekuens primernya tanpa membandingkan dengan struktur protein lain. Terdapat banyak kemungkinan dalam pendekatan ini, misalnya dengan menirukan proses pelipatan (folding) protein dari sekuens primernya menjadi struktur tersiernya (misalnya dengan simulasi dinamika molekular), atau dengan optimisasi global fungsi energi protein. Prosedur-prosedur ini cenderung membutuhkan proses komputasi yang intens, sehingga saat ini hanya digunakan dalam menentukan struktur protein-protein kecil. Beberapa usaha telah dilakukan untuk mengatasi kekurangan sumber daya komputasi tersebut, misalnya dengan superkomputer (misalnya superkomputer Blue Gene [1] dari IBM) atau komputasi terdistribusi (distributed computing, misalnya proyek Folding@home) maupun komputasi grid.
Ekspresi gen dapat ditentukan dengan mengukur kadar mRNA dengan berbagai macam teknik (misalnya dengan microarray ataupun Serial Analysis of Gene Expression ["Analisis Serial Ekspresi Gen", SAGE]). Teknik-teknik tersebut umumnya diterapkan pada analisis ekspresi gen skala besar yang mengukur ekspresi banyak gen (bahkan genom) dan menghasilkan data skala besar. Metode-metode penggalian data (data mining) diterapkan pada data tersebut untuk memperoleh pola-pola informatif. Sebagai contoh, metode-metode komparasi digunakan untuk membandingkan ekspresi di antara gen-gen, sementara metode-metode klastering (clustering) digunakan untuk mempartisi data tersebut berdasarkan kesamaan ekspresi gen.
II. Jelaskan perkembangan BioInformatika di Indonesia!
Saat ini mata ajaran bioinformatika maupun mata ajaran dengan muatan bioinformatika sudah diajarkan di beberapa perguruan tinggi di Indonesia. Sekolah Ilmu dan Teknologi Hayati ITB menawarkan mata kuliah "Pengantar Bioinformatika" untuk program Sarjana dan mata kuliah "Bioinformatika" untuk program Pascasarjana. Fakultas Teknobiologi Universitas Atma Jaya, Jakarta menawarkan mata kuliah "Pengantar Bioinformatika". Mata kuliah "Bioinformatika" diajarkan pada Program Pascasarjana Kimia Fakultas MIPA Universitas Indonesia (UI), Jakarta. Mata kuliah "Proteomik dan Bioinformatika" termasuk dalam kurikulum program S3 bioteknologi Universitas Gadjah Mada (UGM), Yogyakarta. Materi bioinformatika termasuk di dalam silabus beberapa mata kuliah untuk program sarjana maupun pascasarjana biokimia,biologi, dan bioteknologi pada Institut Pertanian Bogor (IPB). Selain itu, riset-riset yang mengarah pada bioinformatika juga telah dilaksanakan oleh mahasiswa program S1 Ilmu Komputer maupun program pascasarjana biologi serta bioteknologi IPB.
Riset bioinformatika protein dilaksanakan sebagai bagian dari aktivitas riset rekayasa protein pada Laboratorium Rekayasa Protein, Pusat Penelitian Bioteknologi Lembaga Ilmu Pengetahuan Indonesia (LIPI), Cibinong, Bogor. Lembaga Biologi Molekul Eijkman, Jakarta, secara khusus memiliki laboratorium bioinformatika sebagai fasilitas penunjang kegiatan risetnya. Selain itu, basis data sekuens DNA mikroorganisme asli Indonesia sedang dikembangkan di UI.
Sumber - Sumber :
Basis data sekuens biologis
Basis data utama untuk sekuens asam nukleat saat ini adalah GenBank (Amerika Serikat), EMBL (Eropa), dan DDBJ(Inggris) (DNA Data Bank of Japan, Jepang). Ketiga basis data tersebut bekerja sama dan bertukar data secara harian untuk menjaga keluasan cakupan masing-masing basis data. Sumber utama data sekuens asam nukleat adalah submisi langsung dari periset individual, proyek sekuensing genom, dan pendaftaran paten. Selain berisi sekuens asam nukleat, entri dalam basis data sekuens asam nukleat umumnya mengandung informasi tentang jenis asam nukleat (DNA atau RNA), nama organisme sumber asam nukleat tersebut, dan pustaka yang berkaitan dengan sekuens asam nukleat tersebut.
Sementara itu, contoh beberapa basis data penting yang menyimpan sekuens primer protein adalah PIR (Protein Information Resource, Amerika Serikat), Swiss-Prot (Eropa), dan TrEMBL (Eropa). Ketiga basis data tersebut telah digabungkan dalam UniProt (yang didanai terutama oleh Amerika Serikat). Entri dalam UniProt mengandung informasi tentang sekuens protein, nama organisme sumber protein, pustaka yang berkaitan, dan komentar yang umumnya berisi penjelasan mengenai fungsi protein tersebut.
BLAST(Basic Local Alignment Search Tool) merupakan perkakas bioinformatika yang berkaitan erat dengan penggunaan basis data sekuens biologis. Penelusuran BLAST (BLAST search) pada basis data sekuens memungkinkan ilmuwan untuk mencari sekuens asam nukleat maupun protein yang mirip dengan sekuens tertentu yang dimilikinya. Hal ini berguna misalnya untuk menemukan gen sejenis pada beberapa organisme atau untuk memeriksa keabsahan hasil sekuensing maupun untuk memeriksa fungsi gen hasil sekuensing. Algoritma yang mendasari kerja BLAST adalah penyejajaran sekuens.
PDB (Protein Data Bank, Bank Data Protein) adalah basis data tunggal yang menyimpan model struktural tiga dimensi protein dan asam nukleat hasil penentuan eksperimental (dengan kristalografi sinar-X, spektroskopi NMR dan mikroskopi elektron). PDB menyimpan data struktur sebagai koordinat tiga dimensi yang menggambarkan posisi atom-atom dalam protein ataupun asam nukleat.
Penyejajaran sekuens
Penyejajaran sekuens (sequence alignment) adalah proses penyusunan/pengaturan dua atau lebih sekuens sehingga persamaan sekuens-sekuens tersebut tampak nyata. Hasil dari proses tersebut juga disebut sebagai sequence alignment atau alignment saja. Baris sekuens dalam suatu alignment diberi sisipan (umumnya dengan tanda "–") sedemikian rupa sehingga kolom-kolomnya memuat karakter yang identik atau sama di antara sekuens-sekuens tersebut. Berikut adalah contoh alignment DNA dari dua sekuens pendek DNA yang berbeda, "ccatcaac" dan "caatgggcaac" (tanda "|" menunjukkan kecocokan atau match di antara kedua sekuens).ccat---caac | || |||| caatgggcaac
Selain itu, sequence alignment juga digunakan untuk mencari sekuens yang mirip atau sama dalam basis data sekuens. BLAST adalah salah satu metode alignment yang sering digunakan dalam penelusuran basis data sekuens. BLAST menggunakan algoritma heuristik dalam penyusunan alignment.
Beberapa metode alignment lain yang merupakan pendahulu BLAST adalah metode "Needleman-Wunsch" dan "Smith-Waterman". Metode Needleman-Wunsch digunakan untuk menyusun alignment global di antara dua atau lebih sekuens, yaitu alignment atas keseluruhan panjang sekuens tersebut. Metode Smith-Waterman menghasilkan alignment lokal, yaitu alignment atas bagian-bagian dalam sekuens. Kedua metode tersebut menerapkan pemrograman dinamik (dynamic programming) dan hanya efektif untuk alignment dua sekuens (pairwise alignment).
Clustal adalah program bioinformatika untuk alignment multipel (multiple alignment), yaitu alignment beberapa sekuens sekaligus. Dua varian utama Clustal adalah ClustalW dan ClustalX.
Metode lain yang dapat diterapkan untuk alignment sekuens adalah metode yang berhubungan dengan Hidden Markov Model ("Model Markov Tersembunyi", HMM). HMM merupakan model statistika yang mulanya digunakan dalam ilmu komputer untuk mengenali pembicaraan manusia (speech recognition). Selain digunakan untuk alignment, HMM juga digunakan dalam metode-metode analisis sekuens lainnya, seperti prediksi daerah pengkode protein dalam genom dan prediksi struktur sekunder protein.
Prediksi struktur protein

Secara kimia/fisika, bentuk struktur protein diungkap dengan kristalografi sinar-X ataupun spektroskopi NMR, namun kedua metode tersebut sangat memakan waktu dan relatif mahal. Sementara itu, metode sekuensing protein relatif lebih mudah mengungkapkan sekuens asam amino protein. Prediksi struktur protein berusaha meramalkan struktur tiga dimensi protein berdasarkan sekuens asam aminonya (dengan kata lain, meramalkan struktur tersier dan struktur sekunder berdasarkan struktur primer protein). Secara umum, metode prediksi struktur protein yang ada saat ini dapat dikategorikan ke dalam dua kelompok, yaitu metode pemodelan protein komparatif dan metode pemodelan de novo.
Pemodelan protein komparatif (comparative protein modelling) meramalkan struktur suatu protein berdasarkan struktur protein lain yang sudah diketahui. Salah satu penerapan metode ini adalah pemodelan homologi (homology modelling), yaitu prediksi struktur tersier protein berdasarkan kesamaan struktur primer protein. Pemodelan homologi didasarkan pada teori bahwa dua protein yang homolog memiliki struktur yang sangat mirip satu sama lain. Pada metode ini, struktur suatu protein (disebut protein target) ditentukan berdasarkan struktur protein lain (protein templat) yang sudah diketahui dan memiliki kemiripan sekuens dengan protein target tersebut. Selain itu, penerapan lain pemodelan komparatif adalah protein threading yang didasarkan pada kemiripan struktur tanpa kemiripan sekuens primer. Latar belakang protein threading adalah bahwa struktur protein lebih dikonservasi daripada sekuens protein selama evolusi; daerah-daerah yang penting bagi fungsi protein dipertahankan strukturnya. Pada pendekatan ini, struktur yang paling kompatibel untuk suatu sekuens asam amino dipilih dari semua jenis struktur tiga dimensi protein yang ada. Metode-metode yang tergolong dalam protein threading berusaha menentukan tingkat kompatibilitas tersebut.
Dalam pendekatan de novo atau ab initio, struktur protein ditentukan dari sekuens primernya tanpa membandingkan dengan struktur protein lain. Terdapat banyak kemungkinan dalam pendekatan ini, misalnya dengan menirukan proses pelipatan (folding) protein dari sekuens primernya menjadi struktur tersiernya (misalnya dengan simulasi dinamika molekular), atau dengan optimisasi global fungsi energi protein. Prosedur-prosedur ini cenderung membutuhkan proses komputasi yang intens, sehingga saat ini hanya digunakan dalam menentukan struktur protein-protein kecil. Beberapa usaha telah dilakukan untuk mengatasi kekurangan sumber daya komputasi tersebut, misalnya dengan superkomputer (misalnya superkomputer Blue Gene [1] dari IBM) atau komputasi terdistribusi (distributed computing, misalnya proyek Folding@home) maupun komputasi grid.
Analisis ekspresi gen

Ekspresi gen dapat ditentukan dengan mengukur kadar mRNA dengan berbagai macam teknik (misalnya dengan microarray ataupun Serial Analysis of Gene Expression ["Analisis Serial Ekspresi Gen", SAGE]). Teknik-teknik tersebut umumnya diterapkan pada analisis ekspresi gen skala besar yang mengukur ekspresi banyak gen (bahkan genom) dan menghasilkan data skala besar. Metode-metode penggalian data (data mining) diterapkan pada data tersebut untuk memperoleh pola-pola informatif. Sebagai contoh, metode-metode komparasi digunakan untuk membandingkan ekspresi di antara gen-gen, sementara metode-metode klastering (clustering) digunakan untuk mempartisi data tersebut berdasarkan kesamaan ekspresi gen.
II. Jelaskan perkembangan BioInformatika di Indonesia!
Saat ini mata ajaran bioinformatika maupun mata ajaran dengan muatan bioinformatika sudah diajarkan di beberapa perguruan tinggi di Indonesia. Sekolah Ilmu dan Teknologi Hayati ITB menawarkan mata kuliah "Pengantar Bioinformatika" untuk program Sarjana dan mata kuliah "Bioinformatika" untuk program Pascasarjana. Fakultas Teknobiologi Universitas Atma Jaya, Jakarta menawarkan mata kuliah "Pengantar Bioinformatika". Mata kuliah "Bioinformatika" diajarkan pada Program Pascasarjana Kimia Fakultas MIPA Universitas Indonesia (UI), Jakarta. Mata kuliah "Proteomik dan Bioinformatika" termasuk dalam kurikulum program S3 bioteknologi Universitas Gadjah Mada (UGM), Yogyakarta. Materi bioinformatika termasuk di dalam silabus beberapa mata kuliah untuk program sarjana maupun pascasarjana biokimia,biologi, dan bioteknologi pada Institut Pertanian Bogor (IPB). Selain itu, riset-riset yang mengarah pada bioinformatika juga telah dilaksanakan oleh mahasiswa program S1 Ilmu Komputer maupun program pascasarjana biologi serta bioteknologi IPB.
Riset bioinformatika protein dilaksanakan sebagai bagian dari aktivitas riset rekayasa protein pada Laboratorium Rekayasa Protein, Pusat Penelitian Bioteknologi Lembaga Ilmu Pengetahuan Indonesia (LIPI), Cibinong, Bogor. Lembaga Biologi Molekul Eijkman, Jakarta, secara khusus memiliki laboratorium bioinformatika sebagai fasilitas penunjang kegiatan risetnya. Selain itu, basis data sekuens DNA mikroorganisme asli Indonesia sedang dikembangkan di UI.
Sumber - Sumber :
- http://id.wikipedia.org/wiki/Mesin_Mealy
- http://id.wikipedia.org/wiki/Mesin_Moore
- http://id.wikipedia.org/wiki/Petri_net
- http://visilubai.files.wordpress.com/2010/06/220px-8-cell.gif
- http://www.komputasi.lipi.go.id/utama.cgi?cetakartikel&1111718762
- http://www.scribd.com/doc/24593215/SEJARAH-KOMPUTASI
- http://www.wikipedia.org/wiki/Bioinformatika